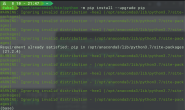
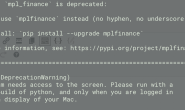
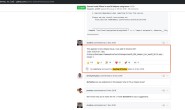
在Ubuntu下,想在终端查询不认识的单词,所以就利用了Python语言,通过正则表达式等知识,对有道单词的网页进行爬取,提取出翻译结果。
#----------------------------------------------------------------
# -*- coding: utf-8 -*-
#!/usr/bin/env python
#----------------------------------------------------------------
# Author : Scharfsinnig
#
# E-Mail : scharfsinnig@163.com
#
# File : WebDict.py
#
# Introduction:
# 脚本主要是对有道网的单词查询网页,进行简单的信息提取任务,找到
# 单词的翻译结果。方便自己在终端下对不认识的单词进行查询。
#----------------------------------------------------------------
import re
import time
import thread
import urllib
import urllib2
from urllib import quote
class Spider_Youdao:
#初始化
def __init__(self):
#有道网页翻译段
self.Trans_Youdao_Tag = re.compile(r’s?<li>.*?</li>s?’)
#21世纪大词典段
self.Trans_Shiji_Tag = re.compile(r’s?<span.*?class="def">.*?</span>’)
#退出标志
self.run = True
#获得查询的单词
def SearchWord(self):
S_Word = raw_input("
#[输入单词]
>")
return S_Word
#得到URL
def GetUrl(self):
SWord = self.SearchWord()
#加上查询的单词以后
if quote(SWord) == SWord:
MyUrl = "http://dict.youdao.com/search?len=eng&q="+quote(SWord)+"&keyfrom=dict.top"
return MyUrl
#获得页面
def GetPage(self):
#获取URL
Youdao_Url = self.GetUrl()
#伪装成浏览器请求
user_agent = ’Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:32.0) Gecko/20100101 Firefox/32.0’
headers = { ’User-Agent’ : user_agent }
req = urllib2.Request(Youdao_Url, headers = headers)
Res = urllib2.urlopen(req)
#将其他编码的字符串转换成unicode编码
ResultPage = Res.read().decode("utf-8")
#ResultPage = Res.read()
return ResultPage
#开始提取网页中的信息
def ExtractPage(self):
#获得页面
MyPage = self.GetPage()
#提取有道的基本翻译
YoudaoTrans = self.Trans_Youdao_Tag
#提取21世纪词典的翻译
ShijiTrans = self.Trans_Shiji_Tag
print "--------------------------------------------"
YouDaoTrans = self.Trans_Youdao_Tag
TransYdIterator = YouDaoTrans.finditer(MyPage)
print "#(翻译来自有道词典):"
myItems = re.findall(’<div.*?class="trans-container">(.*?)<div id="webTrans" class="trans-wrapper trans-tab">’,MyPage,re.S)
for item in myItems:
YDTmp = item
TransYdIterator = YouDaoTrans.finditer(YDTmp)
for iterator in TransYdIterator:
YouDao = iterator.group()
YDTag = re.compile(’s?<.*?>’)
print YDTag.sub(’’,YouDao)
print "--------------------------------------------"
TransSjIterator = ShijiTrans.finditer(MyPage)
print "#(翻译来自21世纪大词典):"
for iterator in TransSjIterator:
ShiJi = iterator.group()
SJTag = re.compile(’s?<.*?>’)
print SJTag.sub(’’,ShiJi)
print "--------------------------------------------"
#启动爬虫
def Start(self):
while self.run:
S_Word = raw_input("
#["!"号退出.回车继续.]
>")
if S_Word != "!":
self.ExtractPage()
#thread.start_new_thread(self.ExtractPage,())
#time.sleep(5)
else:
self.run = False
if __name__ == ’__main__’:
mydict = Spider_Youdao()
mydict.Start()